

浏览量:15390
来源:中国经济网
时间:2023-09-08 10:21
昨日,在北京市科学技术委员会、中关村科技园区管理委员会、北京市海淀区政府的指导下,百川智能召开主题为“百川汇海,开源共赢”的大模型发布会。会上,百川智能宣布正式开源微调后的Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat与其4bit量化版本,并且均为免费可商用。
中科院院士张钹亲临现场并发表致辞
百川智能此次还开源了模型训练的Check Point,并宣布将发布 Baichuan 2技术报告,详细介绍Baichuan 2的训练细节,帮助大模型学术机构、开发者和企业用户更深入的了解其训练过程,更好地推动大模型学术研究和社区的技术发展。
文理兼备,性能大幅优于同尺寸模型
Baichuan2-7B-Base 和 Baichuan2-13B-Base,均基于 2.6万亿高质量多语言数据进行训练,在保留了上一代开源模型良好的生成与创作能力,流畅的多轮对话能力以及部署门槛较低等众多特性的基础上,两个模型在数学、代码、安全、逻辑推理、语义理解等能力有显著提升。其中Baichuan2-13B-Base相比上一代13B模型,数学能力提升49%,代码能力提升46%,安全能力提升37%,逻辑推理能力提升25%,语义理解能力提升15%。
本次开源的两个模型在各大评测榜单上的表现优秀,相比其他同等参数量大模型,表现亮眼,性能大幅度优于LLaMA2等同尺寸模型竞品。
更值得一提的是,根据MMLU等多个权威英文评估基准评分 Baichuan2-7B以70亿的参数在英文主流任务上与130亿参数量的LLaMA2持平。
Baichuan2-7B和Baichuan2-13B不仅对学术研究完全开放,开发者也仅需邮件申请获得官方商用许可后,即可以免费商用。
国内首创全程开源模型训练Check Point,助力学术研究
大模型训练包含海量高质量数据获取、大规模训练集群稳定训练、模型算法调优等多个环节。每个环节都需要大量人才、算力等资源的投入,从零到一完整训练一个模型的高昂成本,阻碍了学术界对大模型训练的深入研究。
百川智能本次开源了模型训练从220B到2640B全过程的 Check Ponit。这对于科研机构研究大模型训练过程、模型继续训练和模型的价值观对齐等极具价值,将极大推动国内大模型的科研进展,开源训练模型过程对国内开源生态尚属首次。
技术报告揭示训练细节,繁荣开源生态
为帮助从业者深入了解Baichuan 2的训练过程和相关经验,更好地推动大模型社区的技术发展。百川智能在发布会上宣布,公开Baichuan 2的技术报告。技术报告将详细介绍Baichuan 2 训练的全过程,包括数据处理、模型结构优化、Scaling law、过程指标等。
百川智能自成立之初,在不到四个月的时间内相继发布了Baichuan-7B、Baichuan-13B两款开源免费可商用的中文大模型,以及一款搜索增强大模型Baichuan-53B,两款开源大模型在多个权威评测榜单均名列前茅,目前下载量超过500万次。
不仅如此,在今年创立的大模型公司中,百川智能是唯一一家通过《生成式人工智能服务管理暂行办法》备案,可以正式面向公众提供服务的企业。凭借行业领先的基础大模型研发和创新能力,此次开源的两款Baichuan 2大模型,得到了上下游企业的积极响应,腾讯云、阿里云、火山方舟、华为、联发科等众多知名企业均参加了本次发布会并与百川智能达成了合作。
未来,百川智能将在开源大模型领域持续深耕,将更多的技术能力、前沿创新开放出来,与更多的合作伙伴们共同助力中国大模型生态蓬勃发展。
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
9月2日,以“开放引领发展,合作共赢未来”为主题的2023年中国国际服务贸易交易会盛大开幕。在由中国国家广播电视总局和英国商业贸易部共同举办的“2023中英视听产业合作对话”活动中,中国广播电视总局...
2023-09-08 09:08
针对网传“旅客携带充电宝进高铁站被拦”,广铁集团深圳北火车站6日晚在官方微博发布情况说明。 9月6日上午,虎门站安检工作人员发现一名旅客携带了额定能量为148Wh的充电宝,依...
2023-09-07 11:40
9月7日,玩出梦想品牌迎来全面升级,品牌名由大众熟知的“YVR”正式更名为“玩出梦想”,此前的“YVR品牌”则将作为公司VR产品线的子品牌名继续保留。 同时,玩出梦想启用全新...
2023-09-07 11:33
面对人们多元化、个性化的健康消费需求,健康产品及服务也在推陈出新。9月,京东买药联合百大健康品牌,推出“康康开新开心百分百”活动,覆盖医药、营养保健、医疗器械、消费医疗等品类,...
2023-09-06 10:37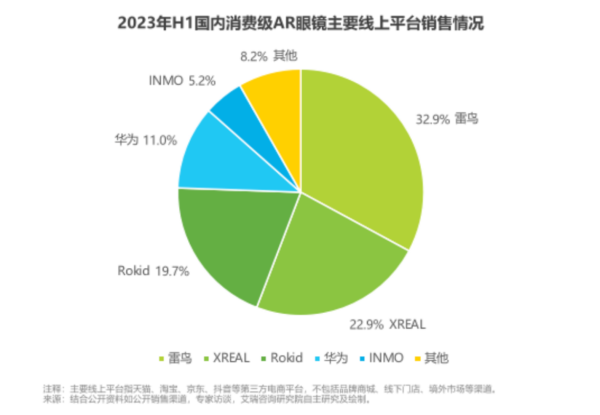
据第三方数据机构艾瑞咨询发布2023年H1国内消费级AR眼镜主要线上平台市场销售报告显示,雷鸟创新延续上一年优势并进一步扩张,以32.9%的市场占有率稳居第一。 艾瑞咨询预测...
2023-09-05 15:58
“怎么才能进入这个直播间?”9月4日,2023年中国国际服务贸易交易会现场,一位来自主宾国英国的参会代表,对BOSS直聘展台的直播带岗活动产生了浓厚的兴趣。 当天上午正在进行...
2023-09-05 15:29
9月2日,2023年中国国际服务贸易交易会在北京举行,此次服贸会以“开放引领发展,合作共赢未来”为主题,吸引2400余家企业线下参展,包括世界500强和行业龙头企业500多家。...
2023-09-05 12:03北京时间2023年9月5日,携程集团公布了截至2023年6月30日第二季度未经审计的财务业绩。2023年第二季度,携程集团净营业收入为112亿元,同比增长180%,超过2019年同期29%,业绩表现...
2023-09-05 10:10



